Improving incentives for web advertisers
August 10th, 2011When users install ad filters out of a desire to avoid unpleasant ads, they usually end up blocking all ads. This does little to incentivize individual sites to clean up their ads, because from the perspective of any web site owner, users decide whether to block ads mostly based on their experiences on other sites.
As more users turn to ad filters, debates about ad filtering are becoming increasingly polarized. A pro-ad faction screams “blocking ads is like stealing from web sitesâ€. An anti-ad faction screams “showing me ads is like kicking me in the groin in the hope that a penny will fly out of my pocketâ€.
A better way?
What if a future version of Adblock Plus only tried to block bad ads by default? The immediate result would be negligible, because most ad networks today are somewhere between bad and terrible. But some users would feel more comfortable enabling the blocks, and web site owners would have a harder time blaming visitors for missed revenue.
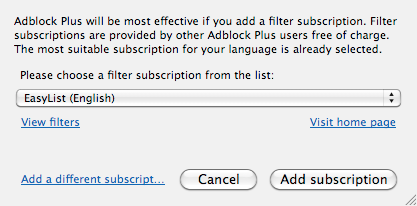
Current Adblock Plus first run page
“Block distracting ads†would block ads that animate, ads with bright pink, gigantic ads, <audio> ads, ads that use absolute positioning to cover other content, and plugins.
“Block slow ads†would block ad scripts that do not use async or defer, any ad that uses more than 5 sequential or 10 total requests, any ad content that hasn't finished loading after 500ms, and plugins.
Note that these are all things that can be detected by the client, which already has a filter set that distinguishes ads from non-ads. Upon blocking an ad through one of these heuristics, the entire ad network should be blocked for a period of time, so that Firefox does not waste time downloading things it will not display. The filter set could also specify ad networks known to specialize in distracting ads, or ad networks that are slow in ways the heuristics miss.
Blocking manipulation
The heuristics above would block ads that interfere directly with your web experience, but what about ads that harm you in slightly subtler ways? Maybe activists would be inspired to curate subsets of existing filters, focusing on their causes:
| e.g. lingerie, “adult dating†| |
| e.g. action films, appeals to fear | |
| e.g. junk food, tobacco | |
| [?] | e.g. toys, nag coaching |
These would block almost every ad network today, assuming the curators err on the side of over-blocking when a network carries multiple types of ads. I can only name one ad network that demonstrates the slightest bit of competence at keeping out scams and one ad network that actively gathers feedback from viewers about individual ads.
With improved incentives, more ad networks would try to do the right thing.
I look forward to a future where advertising is a truly low-transaction-cost way to compensate free content providers.
I look forward to innovators and creators once again having a way to connect with people who might genuinely stand to benefit from their work, without having their voices drowned out by screaming scammers.
{kind=link}
{kind=link}