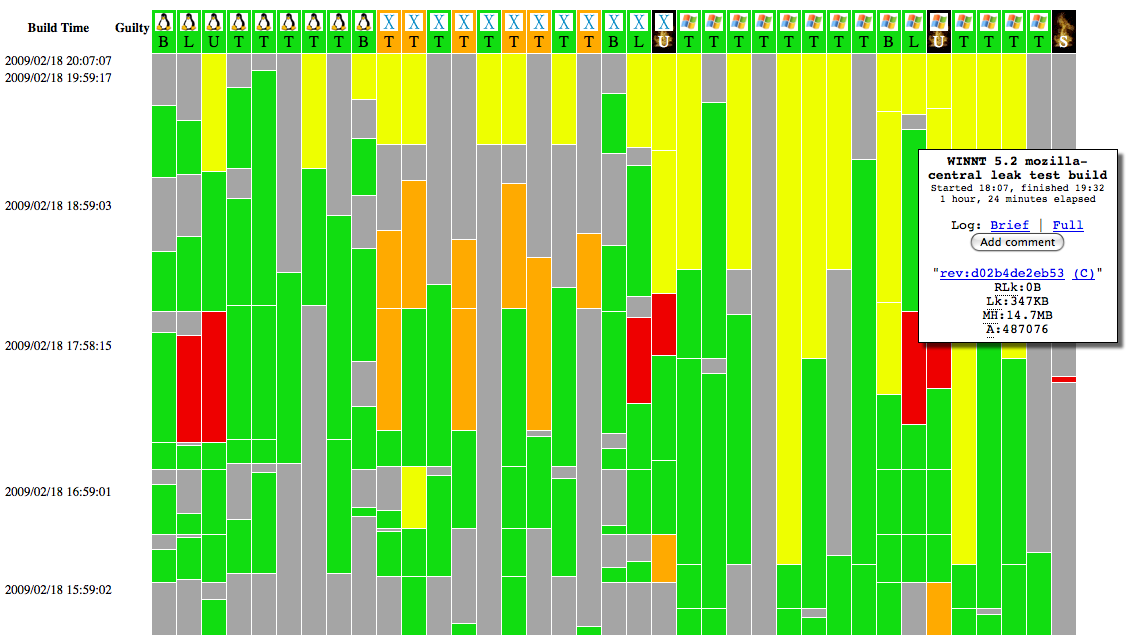
Mozilla's poor continuous-integration story is a major source of stress and wasted time for Mozilla developers. Andreas Gal, for example, recently lost two consecutive weekends tracking down test failures. The story is all too common:
Numb to everyday "random orange" from intermittent failures, nobody noticed the new test failures until there were multiple new test failures. Many patches occupied each regression window, due to long test cycle times, combined with many developers sharing few opportunities to land. Backing out the potentially-responsible changesets one at a time required merging and waiting through the long cycles again.
Fixing these problems will require more than incremental improvements to the Tinderbox display. It will require, at the very least, rethinking how we organize and visualize the data coming off of our build machines. It may even require changes to the way we allocate build machines and check in code.
Recent work
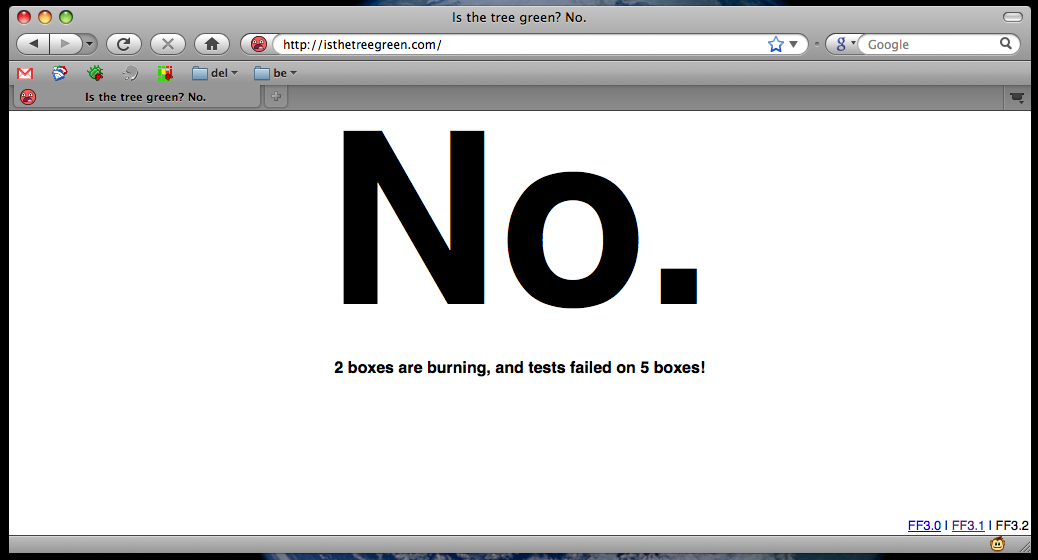
Over the last few months, there has been an explosion of client-side Tinderbox modifications and mashups. Here's what we have now:
Other people in the Mozilla community are also interested in improving the continuous integration experience:
Why we load Tinderbox
- Developers
- Can I pull safely?
- Can I push now?
- Did I avoid breaking the tree so far?
- Can I go to sleep now?
- Sheriffs / firefighters
- Is any column missing?
- Has anything gotten slower?
- What patch caused that slowdown?
- What patch caused that test failure?
- How do I get the tree green again?
- Build engineers
- Is any machine missing or unhealthy?
- Which columns have long cycle times?
- What changes needed clobbers, indicating makefile bugs?
- Test engineers
- What tests do we have?
- What tests especially good at catching real bugs?
- What tests are we skipping?
- What tests are unreliable?
- What tests are unreasonably slow, and maybe not worth running on every build if they can't be sped up?
Tinderbox tries to answer all these questions with a single <table>. As a result, it answers none of them well.
We can design better systems for answering each of these questions, but first, I'd like to present an idea for eliminating the need to ask the questions in bold.
Try-to-push
By integrating the Try concept directly into the way we work, we can make the answer to the first four questions be always yes. Under this proposal, instead of pushing to mozilla-central, everyone pushes to a server that runs all the tests, and if the tests pass, automatically pushes the changes to mozilla-central.
Then it is always ok to pull or push, because mozilla-central is always green. If my patch breaks something, it's immediately clear that it was my patch, and I don't have to be around to back it out. I haven't wasted anyone else's time or prevented anyone else from checking in.
When there are multiple pending changesets, the automatic push should include a rebase (or hg merge, but that's probably more painful). If my patch's rebase fails, my patch doesn't end up on mozilla-central, but I claim that the occasional automatic-merge failure (requiring additional action from only one developer) is less painful than the frequent backouts we have now.
Developers should be warned up-front if a patch will require manual merging in the case that other pending changesets succeed. We should have the option of basing changes on any pending changeset in addition to mozilla-central, with the caveat that if the base fails, our changeset will not go in either. And of course, we should still be able to use Try to test a changeset without intending for it to go onto mozilla-central immediately.
Reducing cycle time
We can decrease cycle times drastically by splitting up the testing work more sanely. Instead of having four unit test machines each testing a different revision (reporting to the same column), have each machine run a quarter of the tests. When the tree is calm, results will be available in a quarter of the current amount of time; when the tree is busy, it won't be any slower.
The cycle time goal for most machines should be the same. Otherwise, we're using our resources inefficiently, because a checkin isn't done cycling until all the tests are finished. We can make exceptions for especially slow tests, such as Valgrind, static analysis, or code coverage, but these slow tests shouldn't be allowed to turn the tree orange in the same way as other tests.
Finding performance regressions
Don't make me load 53 graphs, each of which takes 6 seconds to load. Don't even make me eyeball 20 graphs. Instead,
Just tell me if I make Firefox slower. (Also tell me if I increase the variance enough to make it hard to spot future slowdowns.)
Using an algorithm frees us to track more performance data, such as the time taken on of each component of SunSpider. If a patch makes a single SunSpider file 5% slower, that might be noise as part of the total SunSpider score, but obvious from looking at just that one file.
An algorithm might be slightly worse or slightly better than a human at noticing numeric changes, but it's a hell of a lot more patient.
Understanding test failures
Make it easier to see which test failed. The "short log" isn't really short, and even the summary often includes extraneous information. Just tell me which tests failed and show the log from the execution of those tests.
Ted Mielczarek is working on making Tinderboxen produce stack traces for crashes. This will make it possible to debug many issues quickly, even if we can't reproduce them. Samples for hangs would useful in the same way.
It would be great if at least some of the boxes used record-and-replay to make it possible to debug other issues, including timing issues such as non-hang timeouts and race conditions. Ideally, I'd be able to replay in a VM on my own machine and debug the issue as it unfolds.
Fixing unreliable tests
Random oranges don't have to happen. If IMVU can eliminate random oranges while testing with Internet Explorer, we can do it while testing our own products.
The first step to fixing unreliable tests is finding out which tests are unreliable. Currently, it takes a very observant sheriff to notice that the same test has failed twice in a week. Even then, we can't search to see when the test began failing, so we don't know whether to disable the test or hunt for a regressing bug. We need a searchable database of test failures.
The next step is figuring out whether the test or the code is unreliable. For now, the answer is often "mark the test as 'skip' and hope we can figure it out later", which is better than distracting everyone with random orange, but not ideal. Again, record-and-replay is probably the only reliable way to find out.
Another approach to fixing unreliable tests is to use tools designed to hunt for unreliability. Valgrind's memcheck can find the uninitialized-variable and use-after-free bugs that only lead to crashes occasionally. Valgrind's helgrind can detect many types of race conditions. Unless we build our own botnet, Valgrind tests will be too slow to be allowed to turn the tree orange, but they will give us insight into some types of bugs that cause random failures on normal test machines.
Design lunch
It's going to take a lot of work from designers and engineers to make continuous integration work well at Mozilla's new scale, but I think the potential payoff in increased developer productivity makes it worth the effort to get this stuff right.
I've only proposed ways to answer some of the questions more efficiently. I'm just an observer -- not really a Mozilla developer, and definitely not a build engineer -- so I might have missed some important points.
John O’Duinn will host a design lunch on this topic tomorrow (Thursday, February 19, noon in California).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}